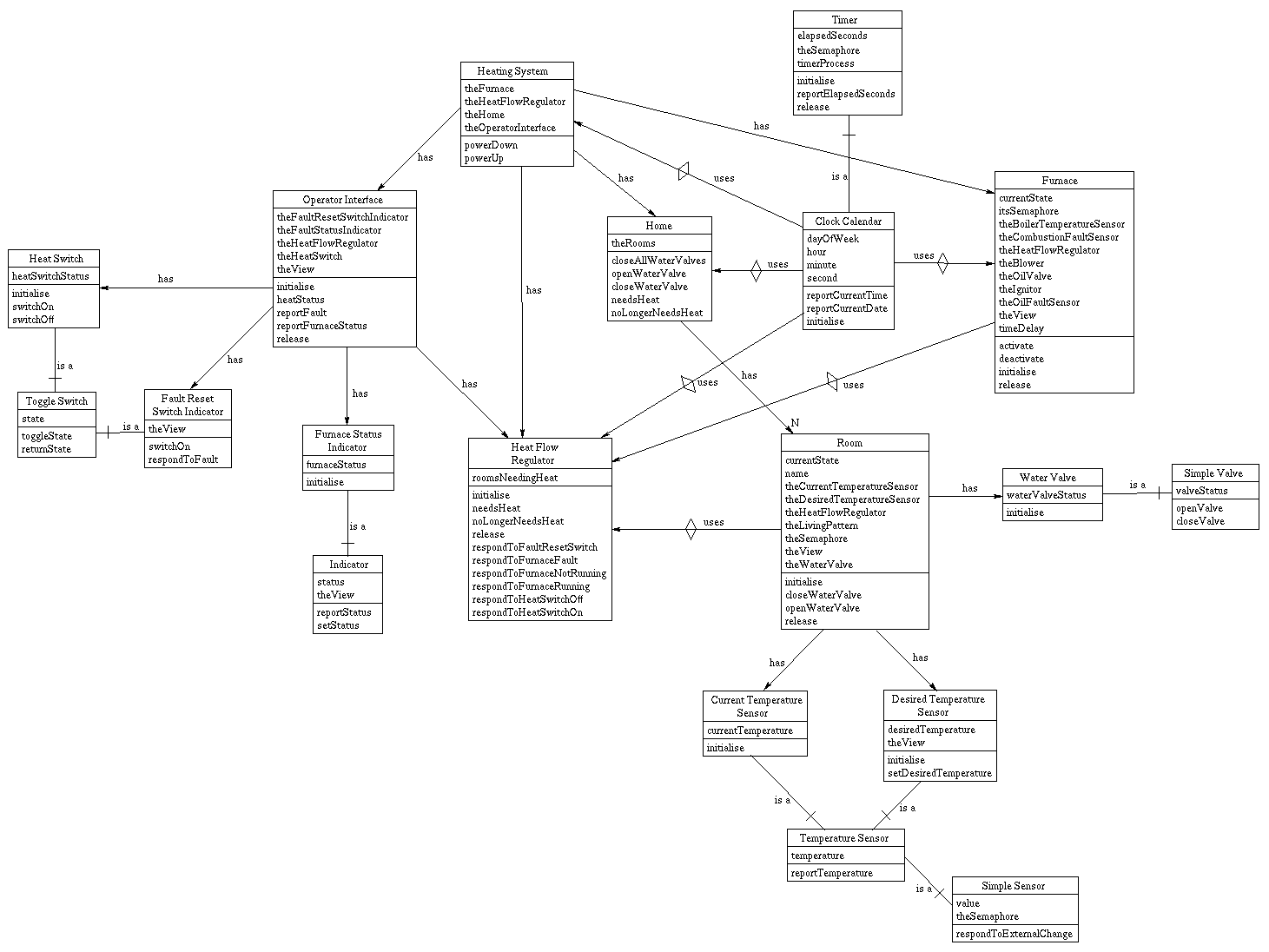
What is a Database?
by Spencer Wade
The term database refers to any organized collection of data. This data is typically organized to model aspects of reality in a way that supports processes requiring this information. The term is correctly applied to data and the supporting data structures, but not to the database management system, or DBMS. A database data collection with DBMS is known as a database system.
It is implied by the term database system that the data is managed to some level of quality. This is usually measured in terms of accuracy, availability, usability, and resilience. The quality management seen in the database system is evidence of a general-purpose database management system. A general-purpose DBMS is a complex software system that meets many usage requirements to properly maintain its often large and complex databases.
The use of client-server, real-time transactional systems where multiple users have access to data highlights the importance of DBMS. In these systems, data is concurrently entered and inquired for in ways that preclude single-thread batch processing. Most of this requirement complexity can be found in personal desktop-based database systems.
There are many well-known DBMSs available today. These include DBMSs from Oracle, FoxPro, IBM DB2, MySQL, SQLite, Sybase, Linter, Microsoft Access, Microsoft SQL Server, and PostgreSQL. Databases are not usually portable across different DBMS, but different DBMSs can interoperate to some degree using standards like SQL and ODBC together to support a single application built over more than one database. DBMSs must also provide effective runtime execution to properly support, in terms of performance, availability, and security, as many database end-users as needed.
The classification of databases is directly related to their contents. Bibliographic databases, document-text databases, statistical databases, and multimedia objects databases are just a few examples of the different types. Databases can also be classified by their application area. Examples of this classification method include accounting, movies, banking, manufacturing, music compositions, and insurance. The term database may be narrowed to specify particular aspects of the organized collection of data, and may refer to the logical database, the physical database as data content in computer storage, or to many other sub-definitions.
Database Concept
The concept that led to the development of the database has been evolving since the 1960s. This was primarily due to the increasing difficulties in designing, building, and maintaining complex information systems. This was especially true when dealing with systems that have multiple concurrent end-users, and contain a large amount of diverse data. Database management systems have evolved as well in order to facilitate the effective handling of databases. DBMSs and databases are different entities, but they are inseparable. A database’s properties are determined by its supporting DBMS.
It is believed, though it may be argued, that a 1962 technical report was the first to use the term “data base”. In the intervening years, there have been enormous strides made in processing power and speed, computer memory and storage, and computer networking. This growth has been reflected in the size, capability, and performance of databases and their respective DBMS. For many years, it has been deemed unlikely that any complex information system could be built effectively without a proper database supported by a DBMS. Database usage has spread to such a degree that virtually every technology and product relies on databases and DBMS for its development and commercialization, and companies and organizations rely heavily on them for their operations as well.
There is no clear, accepted definition of DBMS, but it is widely accepted that a system must provide considerable functionality to qualify as one. Its supported data collection must also meet usability requirements to be considered a true database. This basically means that a database and its DBMS are loosely defined by a general set of requirements. All existing mature DBMS meet these requirements to a great extent, and less mature DBMS strive to meet them or are converging to meet them.
Evolution of Database and DBMS Technology
The definition of the term database, as was discussed earlier, coincided with the availability of direct-access storage from the mid-1960s onwards. It represented a fundamentally different approach from the tape-based systems of the past, and allowed shared interactive use rather than simple daily batch processing.
The earliest database systems were primarily concerned with efficiency, but developers already recognized that other important objectives existed. One of these objectives focused on making data independent of the logic application programs, so that this data could be shared among the different applications. This was a groundbreaking change in database development and usage.
Since the 1970s, there has been an exponential increase in capacity and speed of disk storage and main memory on computing platforms. Database technology has kept pace with this explosion, and by doing so has enabled the creation of ever larger databases and higher throughput volume. This has allowed the development of many of the applications we use on a daily basis; both in personal life and business.
The general-purpose database, in the beginning, was navigational. The applications would typically access the data by following pointers from one record to another. At this point in database development, there were two main data models being used. The hierarchical model used by the IBM IMS system, and the Codasyl model implemented in products like IDMS. This remained the case until 1970.
It was then that Edgar F. Codd proposed the relational model. This model departed from the norm by insisting that applications should search for data by content rather than following links. This was necessary to allow the content of the database to evolve without constant rewriting of links and pointers. The relational model consists of ledger-style tables that each correspond to a different type of entity. Any new data may be freely inserted, deleted, and edited in these tables, and the DBMS is responsible for maintenance necessary to present a table view to the application/user.
The term relational comes from entities referencing other entities in what is known as a one-to-many relationship like a hierarchical model, and a many-to-many relationship like a network model. So, a relational model can express both navigational and hierarchical models as well as its tabular model. This allows for pure or combined modeling as the specific application requires.
Relational models, in their earliest forms, did not make relationships between different entities explicit in the way users were accustomed to, but as primary keys and foreign keys. These keys can be seen as pointers, of a sort, stored in tabular form. The use of keys rather than pointers obscured relations between entities in the way it was presented, so the relational model was considered to emphasize search over navigation. It was deemed a good conceptual basis for a query language, but not so for a navigational language.
This gave rise to the development, in 1976, of the entity-relationship model. This model gained instant popularity for database design since it emphasized a more familiar description than the earlier relational model. In time, entity-relationship constructs were retrofitted as data modeling constructs for relational models, and the differences between the two became irrelevant.
Relational system implementations lacked the automated optimizations of conceptual elements and operations when compared to their physical storage and processing counterparts. Their simplistic and literal implementations placed heavy demands on the limited processing resources of the time. It took the arrival of the mid-1980s, with its increases in computing power, for relational systems (DBMSs and applications) to be widely deployed. In the 1990s, relational systems became the dominant system used for large-scale data processing applications, and still hold that lofty spot today. The dominant database language for the relational model is SQL which has influenced the evolution of many other database languages.
The inflexibility of the relational model has increasingly been seen by users as a limitation when dealing with information that is richer or more varied than the traditional “ledger book” data of corporate information systems. This issue is most prevalent when modeling multimedia databases, molecular science databases, document databases, and engineering databases. The rigidity in the relational model is due to the need to represent new data types other than text and text-alikes. Examples of unsupported data types include:
- Graphics – Pattern-matching and OCR
- Multidimensional Constructs – 2D geographical, 3D geometrical, and multidimensional hypercube models.
- XML – Hierarchical data modeling technology evolved from EDS and HTML used for data interchange among dissimilar systems.
Object-oriented methodologies, focusing on encapsulated data and processes, brought on more fundamental conceptual limitations. Traditional data modeling constructs emphasize the total separation of data from processes, but modern DBMSs allow for limited modeling in terms of validation rules and stored procedures.
Attempts have been made to address the issue of conceptual limitation. Banners such as post-relational or NoSQL are prime examples of this movement. The development of the object database and XML database were noteworthy steps in the right direction, but relational database vendors have combated this competition by extending the capabilities of their own products to support a wider variety of data types.
Final Thoughts
Database technology has grown from its archaic origins into an ever-changing field of complex technical innovation. There are breakthroughs being made every day that open up the possibilities offered by databases and DBMSs, and this will only expand with the influx of resources being funneled into development from all over the world. The next few years should be a very exciting time for database users. The sky is the limit for this technology moving forward.